原来的方式搭建都是直接在宿主机上面搭建的,可是我现在只有一台宿主机,我也想用集群的模式,那就只能用docker的方式搭建了,这里将搭建一个spark主机和两个子机以及hadoop数据节点集群
目录
1、参考以下博文地址搭建基础环境
具体的搭建方式可以参考这篇博文,写的很不错,我也是参考这篇博文搭建的,可惜的是submit的方式提交是可以的,但如果是java的方式提交就不行了,而且搜遍全网和google都没找到有效的解决办法,这也是本片博文需要解决的问题。
以下的链接搭建完后是可以正常使用的,但是会产生几个问题
https://cloud.tencent.com/developer/article/1438344
- 如果只是submit的方式提交没问题,但如果是java spark上下文的方式提交就出问题了
- 我用idea启动了一个spark项目,再提交的时候第一个问题就是宿主机无法与本地机器通信
- 第二个问题就是spark产生的随机端口本地机器无法访问
- 第三个问题就是docker映射端口范围的问题
搭建完成后可以访问
你的宿主机IP:8080
你的宿主机IP:50070
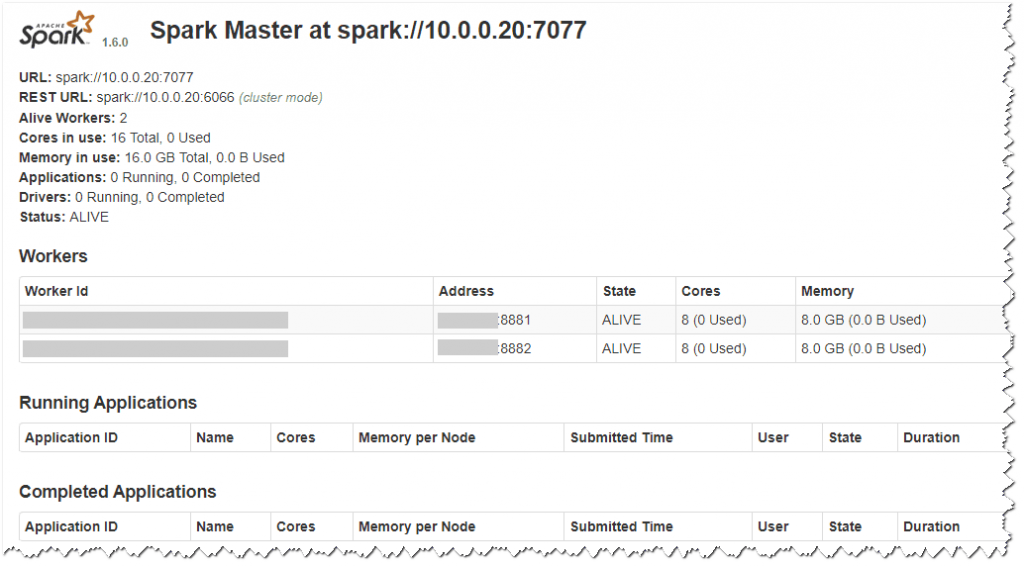
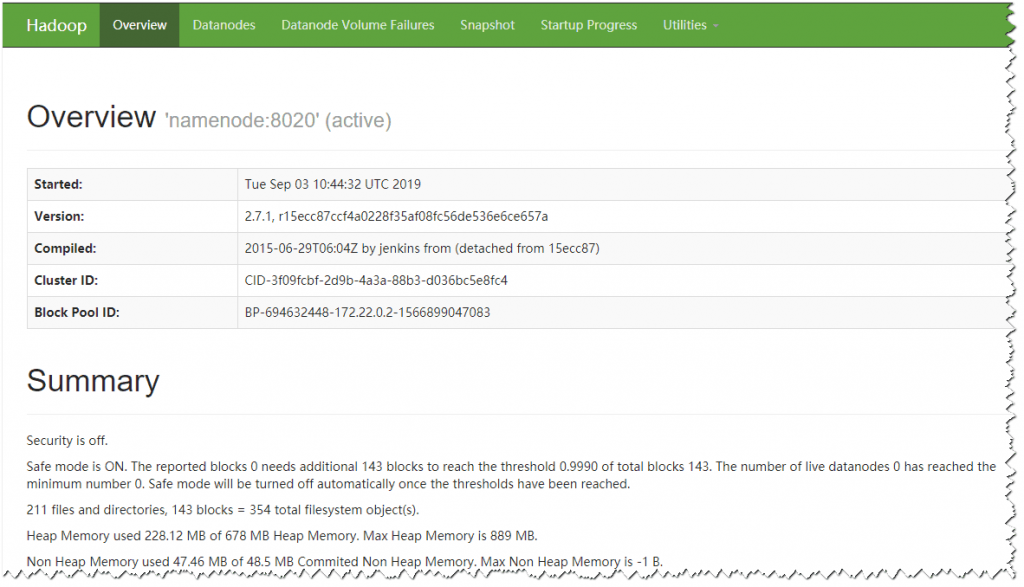
2、针对以上问题直接开门见山请将docker-compose文件修改成如下的方式
下面的worker的配置根据自己宿主机内存和cpu大小分配
version: "2.2"
services:
namenode:
image: bde2020/hadoop-namenode:1.1.0-hadoop2.7.1-java8
container_name: namenode
restart: always
network_mode: 'host'
volumes:
- ./hadoop/namenode:/hadoop/dfs/name
- ./input_files:/input_files
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
resourcemanager:
image: bde2020/hadoop-resourcemanager:1.1.0-hadoop2.7.1-java8
container_name: resourcemanager
restart: always
network_mode: 'host'
depends_on:
- namenode
- datanode1
- datanode2
env_file:
- ./hadoop.env
historyserver:
image: bde2020/hadoop-historyserver:1.1.0-hadoop2.7.1-java8
container_name: historyserver
restart: always
network_mode: 'host'
depends_on:
- namenode
- datanode1
- datanode2
volumes:
- ./hadoop/historyserver:/hadoop/yarn/timeline
env_file:
- ./hadoop.env
nodemanager1:
image: bde2020/hadoop-nodemanager:1.1.0-hadoop2.7.1-java8
container_name: nodemanager1
restart: always
network_mode: 'host'
depends_on:
- namenode
- datanode1
- datanode2
env_file:
- ./hadoop.env
datanode1:
image: bde2020/hadoop-datanode:1.1.0-hadoop2.7.1-java8
container_name: datanode1
restart: always
network_mode: 'host'
depends_on:
- namenode
volumes:
- ./hadoop/datanode1:/hadoop/dfs/data
env_file:
- ./hadoop.env
datanode2:
image: bde2020/hadoop-datanode:1.1.0-hadoop2.7.1-java8
container_name: datanode2
restart: always
depends_on:
- namenode
volumes:
- ./hadoop/datanode2:/hadoop/dfs/data
env_file:
- ./hadoop.env
datanode3:
image: bde2020/hadoop-datanode:1.1.0-hadoop2.7.1-java8
container_name: datanode3
restart: always
depends_on:
- namenode
volumes:
- ./hadoop/datanode3:/hadoop/dfs/data
env_file:
- ./hadoop.env
master:
image: gettyimages/spark:1.6.0-hadoop-2.6
container_name: master
command: bin/spark-class org.apache.spark.deploy.master.Master -h 你的宿主机IP
network_mode: 'host'
restart: always
environment:
MASTER: spark://你的宿主机IP:7077
SPARK_CONF_DIR: /conf
SPARK_MASTER_WEBUI_PORT: 8090
volumes:
- ./conf/master:/conf
- ./data:/tmp/data
- ./jars:/root/jars
worker1:
image: gettyimages/spark:1.6.0-hadoop-2.6
container_name: worker1
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://你的宿主机IP:7077
network_mode: 'host'
restart: always
environment:
SPARK_CONF_DIR: /conf
SPARK_WORKER_CORES: 8
SPARK_WORKER_MEMORY: 8g
SPARK_WORKER_PORT: 8881
SPARK_WORKER_WEBUI_PORT: 8091
volumes:
- ./conf/worker1:/conf
- ./data/worker1:/tmp/data
worker2:
image: gettyimages/spark:1.6.0-hadoop-2.6
container_name: worker2
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://你的宿主机IP:7077
network_mode: 'host'
restart: always
environment:
SPARK_CONF_DIR: /conf
SPARK_WORKER_CORES: 8
SPARK_WORKER_MEMORY: 8g
SPARK_WORKER_PORT: 8882
SPARK_WORKER_WEBUI_PORT: 8092
volumes:
- ./conf/worker2:/conf
- ./data/worker2:/tmp/data
3、为啥得这样修改,我也是无奈之举
首先,如果采用原来的方式搭建的spark集群的话,docker会创建一个桥接网络,里面的所有集群相互通信通过links就可以互相访问这是没有问题的,可是我的本地机器跟这个网络不在一个范围就会有问题如何访问?
我尝试过采用路由映射的方式,路由映射的确可以访问到桥接的内部IP,比如我可以用10段的网络访问到docker内部172段的ip,但是我却无法访问其端口号,你说蛋疼吧,说是防火墙的问题也说是映射的问题,我始终没能解决掉,都尝试了依然无法与容器内部的端口号通信。
最主要的就是任务在计算的时候,spark会产生很多的30000左右的端口号,而且是随机的,如果我们用docker映射端口号是无法确定范围的,docker虽然可以使用范围来确定端口,但是你的docker将会崩溃,因为docker对于端口号的映射一个端口启动一个进程,我映射了500个端口号就已经卡的不行了,而且还容易失败,此方案也被迫放弃
那么让端口号不随机可以吗?答案似乎是不行,但是我是没有找到怎么不让他们随机产生端口号,搜遍google有人碰到跟我一样的问题,依然没有解决方案,有些说用一个bingAddress参数,也许spark2.0以上的可以,可是我的spark版本是1.6的,因为项目原因。如果有用2.0以上的倒是可以试试
4、最终解决方案
我用docker显然不想直接装到宿主机里面,那如何跟我的本地电脑IP保持一个网段呢,就是修改网络模式,docker-compose中的network-mode改为host模式,此模式就是复制宿主机的网络模式,也就是在此模式下,spark生成的所有端口不管是随机的还是固定的都是宿主机的端口号,所以外部就可以轻松访问了,这样呢也就解决了通信问题。
对于数据节点因为我没有找到修改端口号的地方,所以如果都是host模式就会出现端口被占用的情况,如果有人找到了麻烦告诉我一下。
以上呢就是我将自己碰到问题做了个整理,就这个问题我曾两次放弃要不要使用docker搭建spark集群了,而且花费了近一周的时间,但是最终仍然不甘心,肯定会有解决办法的,虽然这种方式并不是优雅的,但的确是解决了我的燃眉之急,如果有更好的解决方案也请告诉我吧。