为什么需要微服务链路追踪?如果有成百上千个微服务在运行,然后每个服务之间都在互相调用甚至调用层级很深,而且每个微服务都会部署到不同的服务器上面,这其中就有很多硬件因素网络因素等,如何知道那个微服务调用慢?如何知道那个微服务调用出错了呢?这一切的处理就需要微服务链路追踪zipkin帮我们追踪和监控,可以很快地排查出那个服务过慢或者出现异常。
本节采用zipkin利用rabbitmq通道接收日志再利用es(elasticsearch)存储输出给kibana展示筛选
目录
1、安装zipkin,rabbitmq,elk
zipkin的安装请参考以下地址
唯一不同的是原来配置的是mysql,现在改用rabbitmq和es,完整yml内容如下
version: '3'
services:
# The zipkin process services the UI, and also exposes a POST endpoint that
# instrumentation can send trace data to. Scribe is disabled by default.
zipkin:
image: openzipkin/zipkin:2.17
container_name: zipkin
environment:
STORAGE_TYPE: elasticsearch
ES_HOSTS: 192.168.113.168:9200
RABBIT_ADDRESSES: 192.168.113.168:5672
# Point the zipkin at the storage backend
TZ: Asia/Shanghai
# Uncomment to enable scribe
# - SCRIBE_ENABLED=true
# Uncomment to enable self-tracing
# - SELF_TRACING_ENABLED=true
# Uncomment to enable debug logging
# - JAVA_OPTS=-Dlogging.level.zipkin=DEBUG -Dlogging.level.zipkin2=DEBUG
network_mode: host
ports:
# Port used for the Zipkin UI and HTTP Api
- 9411:9411
# Uncomment if you set SCRIBE_ENABLED=true
# - 9410:9410
#networks:
# - default
# - my_net #创建网路 docker network create my_net 删除网络 docker network rm my_net
#networks:
#my_net:
#external: true
rabbitmq的安装比较简单,网上找找就好了
elk的安装请参考以下文章地址
2、在用户中心微服务添加相关依赖
这里有注释掉的代码,这部分呢是将日志给logstash收集用的,如果是其他的日志呢,可以采用logstash做收集,这里需要用的日志是微服务链路追踪,所以zipkin更加合适,关于logstash的日志收集没有说,但是配置文件都有相应的配置,也比较简单。
<!-- 微服务链路跟踪 -->
<!--<dependency>-->
<!--<groupId>org.springframework.cloud</groupId>-->
<!--<artifactId>spring-cloud-starter-sleuth</artifactId>-->
<!--</dependency>-->
<!--<dependency>-->
<!--<groupId>net.logstash.logback</groupId>-->
<!--<artifactId>logstash-logback-encoder</artifactId>-->
<!--<version>4.11</version>-->
<!--</dependency>-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
3、修改用户中心下的配置文件
首先修改application.yml文件,完整内容如下
sleuth.sampler.probability是采样率,默认是0.1,这种日志数据量会很大,所以酌情设置
zipkin.sender.type 是日志发送方式,采用rabbitmq发送
server:
port: 8884
eureka:
client:
service-url:
defaultZone: http://cloud-eureka:8801/eureka/
instance:
prefer-ip-address: true
management:
endpoints:
web:
exposure:
include: health,info,hystrix.stream
logging:
level:
root: INFO
org.springframework.web.servlet.DispatcherServlet: DEBUG
spring:
rabbitmq:
host: apg-server
port: 5672
username: guest
password: guest
sleuth:
sampler:
probability: 1.0
zipkin:
sender:
type: rabbit
将spring.application.name挪到bootstrap.yml文件中,因为logback的配置文件需要用到
spring:
application:
name: cloud-user-center
新建logback-spring.xml配置文件,这个文件在本文章中没有用到,因为没有用logstash收集日志,这里贴出来配置可以参考参考
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml" />
<springProperty scope="context" name="springAppName" source="spring.application.name" />
<!-- Example for logging into the build folder of your project -->
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}" />
<property name="CONSOLE_LOG_PATTERN"
value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr([${springAppName:-},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-B3-ParentSpanId:-},%X{X-Span-Export:-}]){yellow} %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}" />
<!-- Appender to log to console -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<!-- Minimum logging level to be presented in the console logs -->
<level>DEBUG</level>
</filter>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file -->
<appender name="flatfile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file in a JSON format -->
<!--<appender name="logstash" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>apg-server:5088</destination>
<!–<encoder class="net.logstash.logback.encoder.LogstashEncoder" />–>
<!–<file>${LOG_FILE}.json</file>–>
<!–<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">–>
<!–<!–<fileNamePattern>${LOG_FILE}.json.%d{yyyy-MM-dd}.gz</fileNamePattern>–>–>
<!––>
<!–</rollingPolicy>–>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"severity": "%level",
"service": "${springAppName:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"parent": "%X{X-B3-ParentSpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>-->
<root level="INFO">
<appender-ref ref="console" />
<!--<appender-ref ref="logstash" />-->
<!--<appender-ref ref="flatfile"/> -->
</root>
</configuration>
4、启动zipkin,rabbitmq,elk以及所有微服务
5、通过网关地址访问用户中心获取订单列表的功能
http://localhost:8802/api/userCenter/userOrderList/1
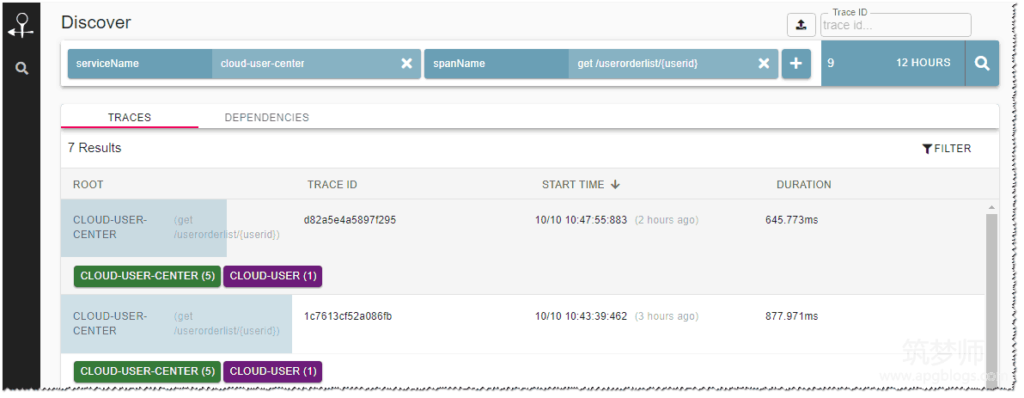
6、打开zipkin查看追踪信息
可以看到调用所花费的时间,以及相关依赖
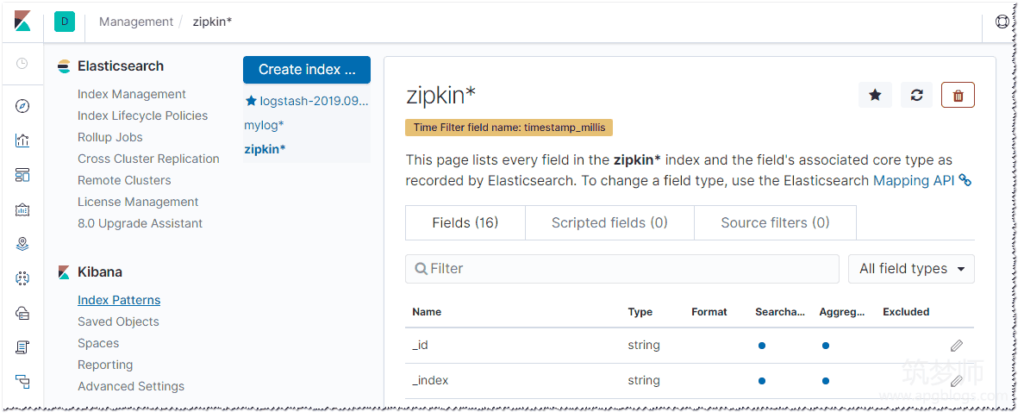
7、再打开kibana查看es的日志信息
以下信息是zipkin的索引,默认是没有的,需要在设置里面添加该索引。
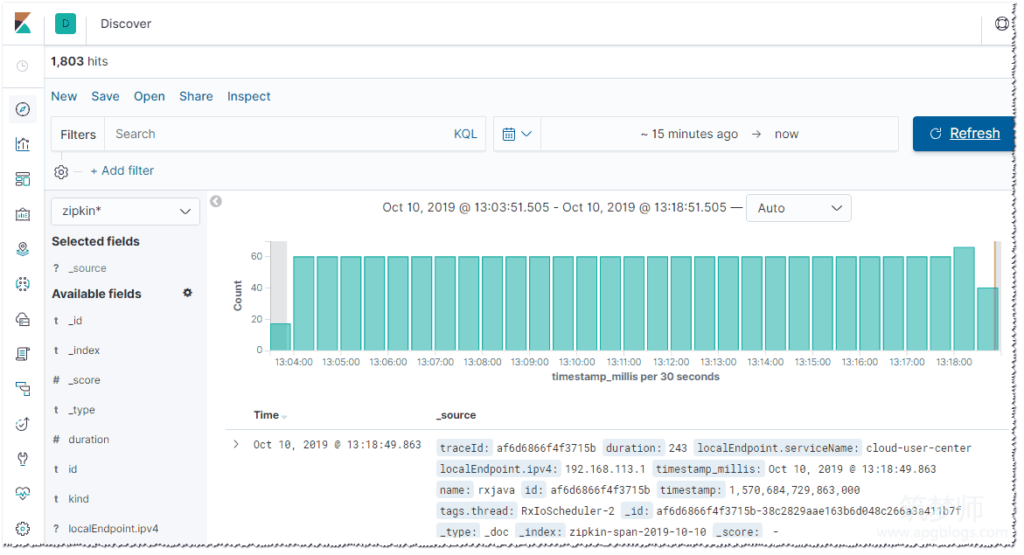
在这里就可以看到zipkin收集过来的日志了
8、文章源码地址
码云:https://gitee.com/apgblogs/springCloudStudy/tree/zipkin/
源码修改补充内容
用docker部署的时候会采用服务编排的方式,所有服务和服务之间的调用是采用服务名,原来的代码中采用的宿主机名,这里需要修改为服务名为docker微服务化做好铺垫
#在开发机器hosts文件中加入以下映射 192.168.113.168 apg-server mysql-db
现在就已经将微服务链路追踪的日志输出给了es和kibana来查看,这样的日志量会非常大,es是很好的选择,源码中很多配置文件和依赖都有所改动,主要是为了docker化做支持,后面将是微服务的部署内容,如何将这些微服务利用docker进行快速部署以及利用maven自动打包镜像